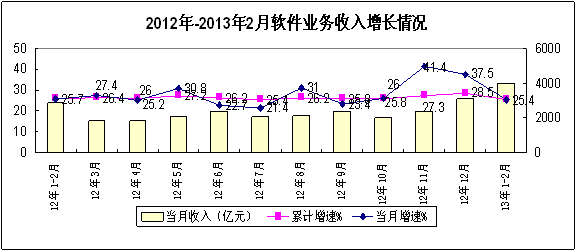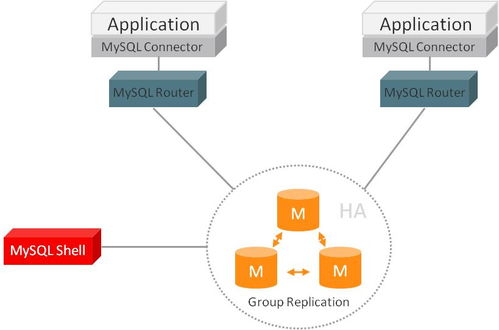
在當今這個信息爆炸的時代,數據已成為驅動社會進步與商業創新的核心生產要素。無論是企業的日常運營、科學研究的前沿探索,還是個人生活的便捷體驗,都離不開海量數據的支撐。而這一切的背后,高效、可靠的數據處理與存儲服務扮演著至關重要的基石角色。它們如同數字世界的“心臟”與“大腦”,負責信息的循環與思考,共同構成了現代信息社會的基礎設施。
數據處理:從原始信息到智慧洞察
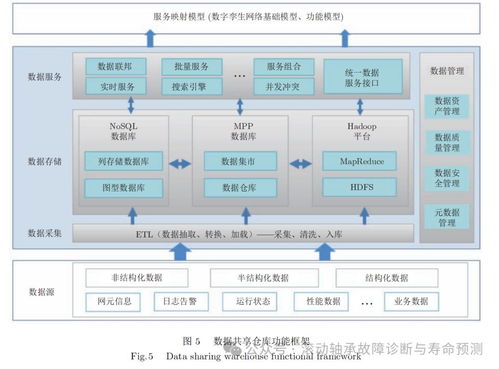
數據處理服務,指的是對原始數據進行采集、清洗、轉換、分析和挖掘,以提取有價值信息、形成知識或支持決策的一系列技術活動。這個過程如同煉金術,將看似無序的“數據礦石”提煉成閃光的“信息黃金”。
數據采集是起點。它通過各種傳感器、日志文件、應用程序接口(API)、網絡爬蟲等手段,從物聯網設備、業務系統、社交媒體等多個源頭匯聚數據。數據清洗與轉換是關鍵步驟。原始數據往往存在格式不一、重復、錯誤或缺失等問題。數據處理服務需要對其進行標準化、去重、糾錯和補全,確保數據質量,并將其轉換為適合分析的統一格式。
核心環節在于數據分析與挖掘。這包括:
- 批量處理:針對歷史數據進行大規模、非實時的分析,常用于生成報表、歷史趨勢分析等。以Hadoop、Spark等為代表的技術框架是此領域的支柱。
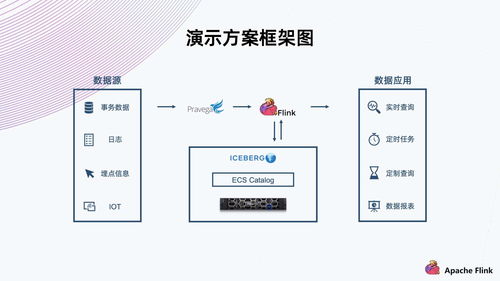
- 流式處理:對持續不斷產生的數據流進行實時或近實時分析,適用于監控、實時推薦、欺詐檢測等場景,如Apache Flink、Kafka Streams等技術。
- 交互式查詢與分析:允許用戶通過查詢語言(如SQL)或可視化工具,靈活、快速地探索數據,獲取即時洞察。
- 機器學習與人工智能:利用算法模型,從數據中自動發現模式、進行預測或分類,是實現智能化的高級階段。
通過這一系列處理,數據從靜態的記錄轉變為動態的洞察,賦能企業優化運營、精準營銷、創新產品與服務。
數據存儲:構筑信息的永恒家園
與處理相輔相成的是數據存儲服務。它負責安全、持久、可擴展地保存數據,確保信息在需要時可被高效訪問。隨著數據量的指數級增長和數據類型的多樣化(結構化、半結構化、非結構化),存儲技術也在不斷演進。
當前主流的存儲服務模式主要包括:
- 對象存儲:適用于存儲圖片、視頻、文檔等非結構化數據。它以“對象”為基本單元,每個對象包含數據、元數據和唯一標識符,具備近乎無限的擴展性和高耐久性。亞馬遜S3、阿里云OSS等是典型代表。
- 塊存儲:將數據劃分為固定大小的“塊”,直接提供給計算實例(如虛擬機)使用,提供低延遲、高性能的存儲,常用于數據庫、企業應用等場景。
- 文件存儲:提供類似傳統文件系統的訪問接口,支持文件目錄結構和標準協議(如NFS、SMB),適合多臺服務器共享訪問同一組文件的場景。
- 數據庫服務:專門用于存儲和管理結構化數據,提供強大的數據操作和查詢能力。又可細分為關系型數據庫(如MySQL、PostgreSQL,強調事務一致性與復雜查詢)和NoSQL數據庫(如MongoDB、Redis,針對高并發、靈活 schema、大數據量等場景優化)。
現代數據存儲架構還強調分層存儲,根據數據的訪問頻率和重要性,將其自動存放在性能、成本不同的存儲介質上(如高速SSD、標準硬盤、歸檔磁帶),實現成本與效率的最佳平衡。數據安全與合規性也是存儲服務的生命線,包括加密(傳輸中與靜態)、訪問控制、備份與容災等技術,確保數據不被泄露、丟失或篡改。
云服務:數據處理與存儲的新范式
云計算的出現,極大地改變了數據處理與存儲服務的提供和消費方式。公有云提供商(如AWS、Azure、Google Cloud、阿里云、騰訊云等)將強大的計算、存儲、網絡資源以及豐富的數據服務(如數據倉庫、數據湖、機器學習平臺)以服務的形式提供。企業無需自建昂貴的數據中心,即可按需獲取彈性的、全球化的數據處理與存儲能力,實現快速創新和成本優化。
數據湖與數據倉庫的融合架構成為趨勢。數據湖集中存儲所有原始數據,而數據倉庫則存儲經過清洗和建模的、用于分析的結構化數據。結合兩者優勢,企業能夠實現從原始數據到商業智能的全鏈路管理。
挑戰與未來展望
盡管技術日臻成熟,挑戰依然存在:數據隱私與倫理問題日益突出;跨云、跨地域的數據管理復雜度增加;對實時智能處理的需求不斷攀升;以及面對海量數據,如何持續降低存儲與計算成本。
數據處理與存儲服務將更加智能化、自動化和一體化。邊緣計算將數據處理推向數據產生的源頭,以降低延遲。人工智能將更深地融入數據管理生命周期,實現自優化的存儲、自動化的數據質量管理和智能化的分析洞察。隨著量子計算等前沿技術的發展,未來或許將開啟數據處理能力的新紀元。
總而言之,數據處理與存儲服務是數字經濟時代的隱形引擎。它們不僅是技術工具,更是戰略資產。對于任何組織而言,構建或選擇合適的數據處理與存儲服務體系,是挖掘數據價值、贏得競爭優勢的必由之路。在這片浩瀚的數據之海中,駕馭好處理與存儲的雙槳,方能駛向智慧與成功的彼岸。